Here are the trees obtained:
Chart Parser
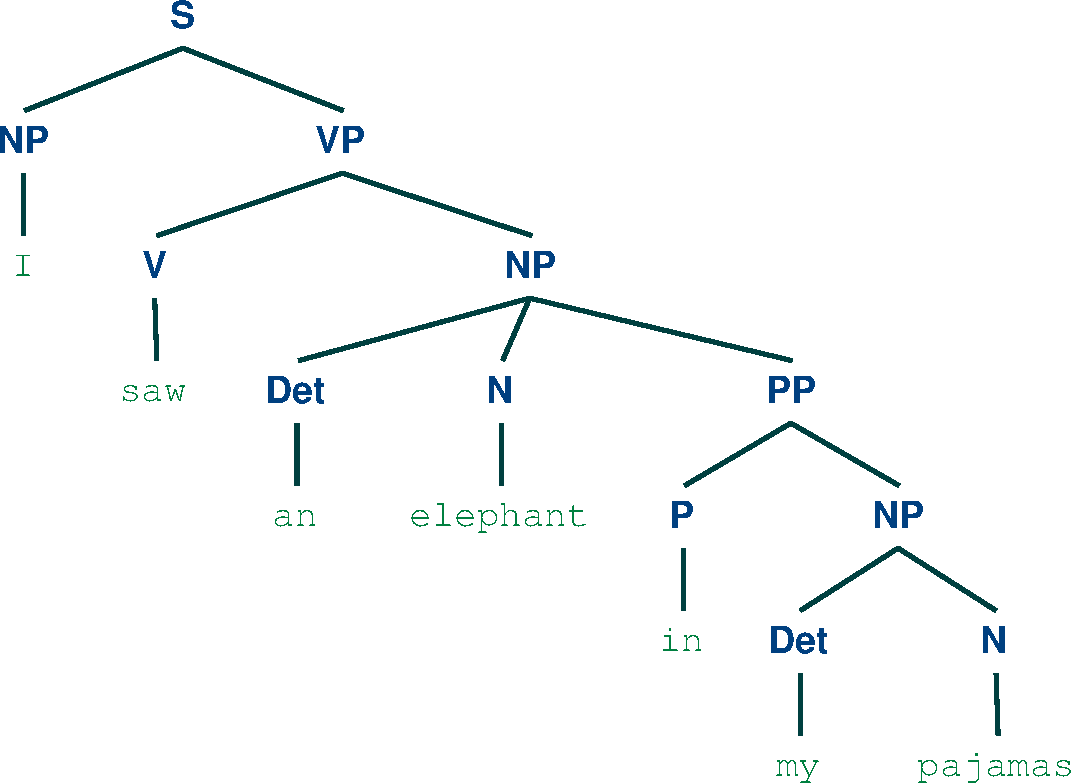
Viterbi Parser
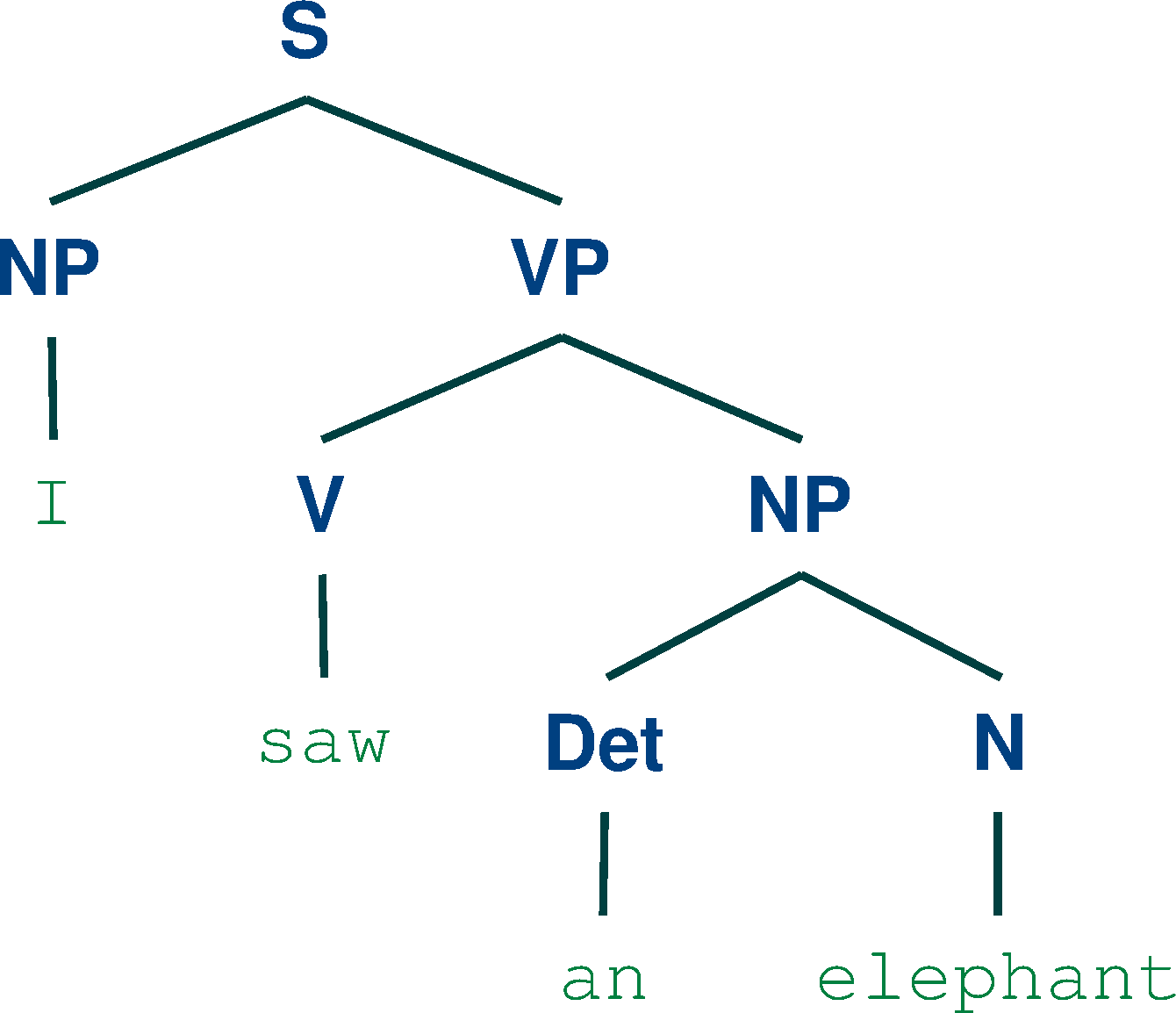
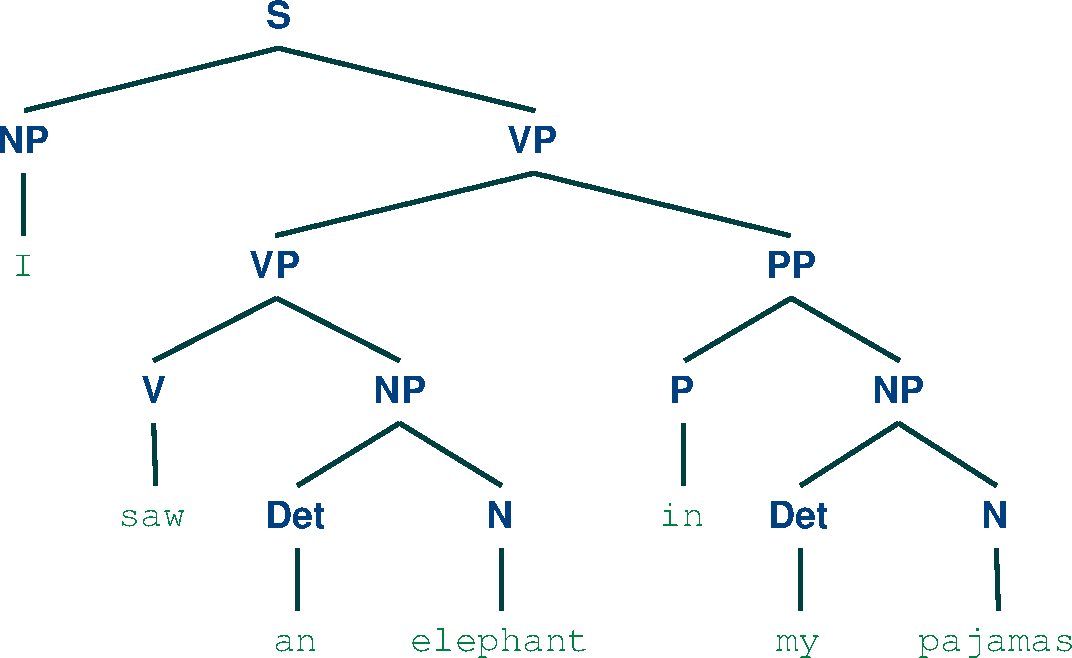
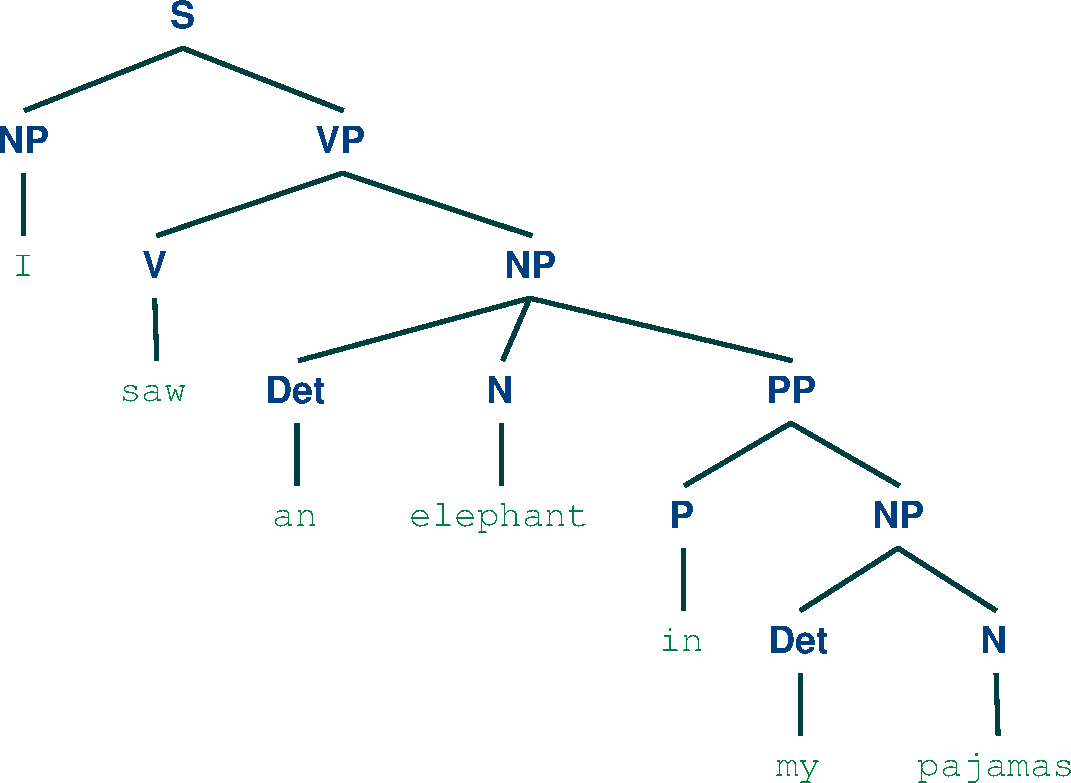
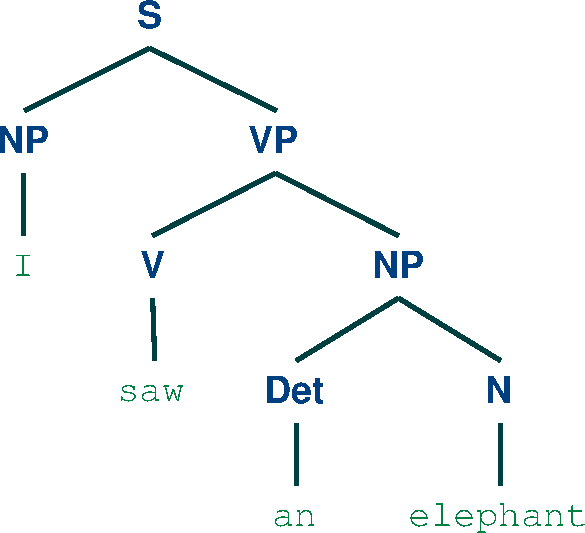
General Concepts Review and Parser Comparison:¶
Before proceeding with the parse analysis, it is important to have a clear idea of what grammars and parse trees represent. Grammars contain sets of rules, which are used to infer the structure of sentences in general. One or more parse trees can be associated to a certain sentence. The parse trees show a possible structure of that particular sentence, which was obtained by applying a sequence of the grammar rules. The root of the tree is always the sentence (S) symbol, because a valid parse needs to yield a valid sentence structure. The leafs of the trees are terminal symbols (i.e words), which are immediately linked to pre-terminal symbols (i.e. PoS tags). The nodes in between the root and the leaves represent the different grammar rules which were applied to obtain that particular parse.
We can notice that for the first sentence, the two the parsers agree on the result. This is due to the more simple structure of the sentence. For the second sentence, the Chart parser finds two parse trees, while the Viterbi parser outputs only one result. This occurs because the Viterbi parser only computes the most probable parse of the sentences, while the Chart parser is not concerned with the probabilities and it searches for all parse possibilities. In this case, we can notice that the most probable parse for the second sentence is the second parse produced by the Chart parser.