Hello Students! 👋 Are you ready to dive into the exciting world of Retrieval-Augmented Generation (RAG) systems? This exercise will guide you through constructing your very own RAG system, combining the power of information retrieval with state-of-the-art language models. Let’s embark on this learning adventure together! First make sure to download the repository from this link: coling_rag_exercise
A Retrieval-Augmented Generation (RAG) system is a powerful AI architecture that combines the strengths of large language models with external knowledge retrieval. Here’s how it works:
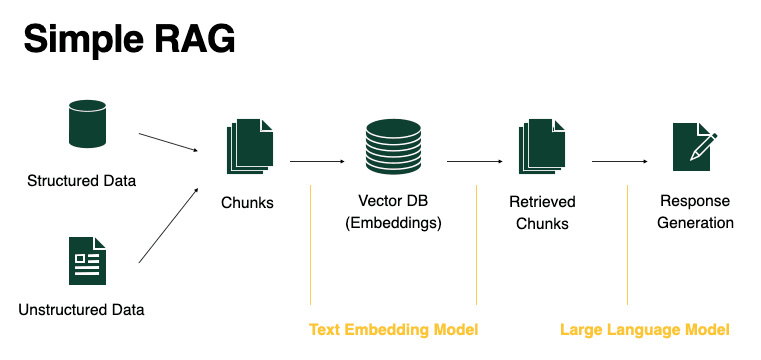
(Image taken from BentoML)
This approach allows the system to access and utilize vast amounts of up-to-date information without the need to retrain the entire model, leading to more accurate and informed responses.
This code has been designed in a Python 3.11 environment. Therefore, to avoid any compatibility issues, we recommend using Python 3.11 for this exercise.
To begin your RAG system journey, you have two options for setting up
your environment: either using venv or conda.
We recommend conda for flexibility.
Create a new Python environment:
python -m venv rag_envActivate the environment:
rag_env\Scripts\activatesource rag_env/bin/activateInstall the required packages:
pip install -r requirements.txtIf you don’t have Conda installed, download and install Miniconda or Anaconda.
Create a new Conda environment with Python 3.11:
conda create -n rag_env python=3.11Activate the Conda environment:
conda activate rag_envInstall the required packages:
pip install -r requirements.txtPlease add a .env file in the root directory of the project with the
following content, so that you can use the OpenAI API. The API key will
be provided during class:
OPENAI_KEY=<your_openai_key> LOCAL=True QUICK_DEMO=True
LOCAL lets you run the embeddings locally if True and on OpenAI’s servers if False., QUICK_DEMO lets you run the code with a smaller dataset for faster results if True and with the full dataset if False.
In the data folder of this project, you’ll find the pdf files of all EPFL legal documents.
Feel free to explore these files to understand the kind of data your system will be working with.
While we’ve provided sample data to get you started, we encourage you to experiment with your own documents and questions! Feel free to replace the provided files with your own text documents and relevant questions. This will allow you to test your RAG system on a wider range of topics and scenarios. To use your own data:
The three new packages we will be using in this practical session are
sqlite3, faiss, and
langchain.
SQLite is a library that implements a small and fast SQL database engine. If you do not know how an SQL database works, do not worry. For these parts of the exercise where you are requested to implement an SQL query, simply ask help from the TAs! The main idea is to use this library as a database to store our documents and their embeddings.
If you are curious, here is a TLDR on how an SQL database works, generated by ChatGPT:
An SQL database works like a digital filing cabinet where data is stored in organized tables. Each table is like a spreadsheet, with rows and columns. Here’s the super simple breakdown: - Tables: Think of a table as a single file in a cabinet. Each table holds information about one topic (like “customers” or “orders”). The columns in the table represent different types of information about that topic (like “name,” “email,” or “order date”), while each row holds a unique entry (like a single customer or one specific order). - SQL Language: SQL (Structured Query Language) is like a set of instructions you use to interact with this filing cabinet. You can ask it to: - Get data with SELECT (like “Show me all the customers in New York”). - Add data with INSERT (like “Add a new customer to the list”). - Update data with UPDATE (like “Change a customer’s email address”). - Delete data with DELETE (like “Remove an old order”). - Relationships: You can connect tables to each other. For example, you might connect the “customers” table to the “orders” table to see which customer made each order. This is called a relationship, and it helps keep things organized and easy to find.
In short, an SQL database stores data in tables, and SQL is the language you use to interact with that data: searching, adding, updating, or connecting pieces of information as needed.
FAISS (Facebook AI Similarity Search) is an open-source library developed by Facebook AI Research (FAIR) that provides efficient algorithms for searching and clustering high-dimensional data such as document embeddings. We will use this library to find the most relevant document to a user query.
LangChain is a framework for developing applications powered by large language models (LLMs). In particular, LangChain will be helpful to be able to create chat sessions with LLM agents like ChatGPT. It conveniently stores the chat history and provides easy ways to create prompt templates without the overhead of having to code it!
Your mission is to complete the missing parts of the RAG system
written in main.py. While you could fill-in the file
directly, we highly recommend following the detailed instructions in
each subsection here. Note that there are many ways to implement some of
these functions (sometimes there isn’t a clear right or wrong), so you
can feel free to choose what functionality to include or not.
To run the main script to test your implementation:
python main.pyTip: Each time you implement a certain portion of the task, try testing that function only.
In this task, you will fill in the
process_pdfandchunk_documentfunctions.
As shown the illustration above, in order to implement a document database that can be easily queried, we need to first vectorize the documents. In order to turn a document into a vector we need to first chunk it into discrete parts that can be easily processed.
process_pdf to chunk the document. For
now you can just implement the first two TODOs.chunk_document and complete all the TODOs.
result
variable where we accumulate the chunks.In this task, you will fill in the
process_pdf,embed_chunksandprocess_and_store_chunksfunctions.
Next step is to store and update chunk embeddings.
process_pdf you will fill in the last TODO
that does the call to process_and_store_chunks.embed_chunks function and complete the
first TODO. You can implement the OpenAI embedding method after you make
it work with the local model.process_and_store_chunks function and
complete all the TODOs.
In this task, you will fill in the
create_faiss_indexfunction.
An index is like a reference or a map that helps you find things quickly.
Imagine you have a huge list of items, and you want to find something in that list. Without an index, you would have to go through the whole list one by one. But with an index, you can go directly to the item you’re looking for, saving time.
In the context of FAISS and similar systems, an index is a structure that stores data in a way that allows for fast search. Instead of comparing every item to the one you’re looking for, the index helps you jump to the closest matches quickly
In the next step, in order to match a query with a document, we have to implement the FAISS indexing system using the L2 distance.
In this task, you will fill in the
search_engine,search_tool,run_agent_conversationfunctions and the global lines between these functions.
Finally, in order to prompt the model with the document we can use a package called LangChain that will easily build the conversation by combining the relevant document and the prompt text for us!
First you need to fill in the TODO in search_engine.
This function takes a question, finds the most relevant chunk in the
database and returns it so you can enhance the question you pass to the
LLM agent. Follow the docstring specs + comments to understand what the
function needs to do and return.
And then you will need to implement the search_tool
function. This function simply uses the search engine to find relevant
information and format them in a human readable way. It’s quite short
because the goal is to provide a function to LangChain as shown right
below the search_tool definition.
Then fill in the TODOs between the
search_tool and run_agent_conversation
functions that create:
Finally, fill-in the run_agent_conversation achieve
the conversation loop:
And voilà! You have completed your RAG pipeline.
Remember, the journey is just as important as the destination. Don’t hesitate to experiment, ask questions, and learn from both successes and failures. Here are some tips:
We’re excited to see what you’ll create! Happy coding, and may your RAG system retrieve and generate with excellence! 🚀📚🤖
Congratulations on building your basic RAG system! However, the journey doesn’t end here. There are several ways to improve and extend your system for better performance and user experience. Here are some areas to consider:
Our current implementation displays the entire message at once, which can lead to long wait times for users. Implementing a chunk-by-chunk response system using LangChain’s streaming capabilities can significantly improve the user experience. This allows users to start reading the response while the rest is still being generated.
The retrieval part of our RAG system can be enhanced in several ways:
Consider fine-tuning your language model on domain-specific data to improve its performance on your particular use case. This can lead to more accurate and relevant responses.
Add a way for users to provide feedback on the system’s responses. This can help you identify areas for improvement and potentially implement a learning mechanism to enhance the system over time.
If your use case involves not just text but also images or other types of data, consider extending your RAG system to handle multiple modalities.
Remember, building a RAG system is an iterative process. Each of these improvements opens up new possibilities and challenges. Don’t hesitate to experiment and push the boundaries of what your system can do!
We’re excited to see how you’ll take your RAG system to the next level. Keep exploring, keep innovating, and most importantly, keep learning! 🚀🧠💡